비지도학습(Unsupervised learning)
비지도학습은 결과정보가 없는 데이터들에 대해서 특정 패턴을 찾는 것을 말한다. 데이터에 잠재한 구조(structure), 계층구조(hierarchy) 를 찾아내는 것, 숨겨진 사용자 집단(hidden user group)을 찾는 것, 문서들을 주제에 따라 구조화하는 것, 로그(log) 정보를 사용하여 사용패턴(usage pattern)을 찾아내는 것이다.
비지도학습의 대상으로는 군집화(Clustering), 밀도 추정(Density estimation), 차원축소(Dimensionality reudction)가 있다.
군집화(Clustering)
군집화란 유사성에 따라 데이터를 분할하는 것을 말한다. 그 예로, 사진관리 시스템이나 영상 분할(segmentation) 등이 있다.

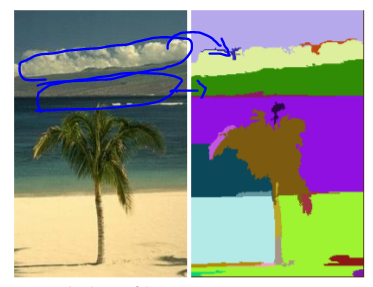
군집화의 종류
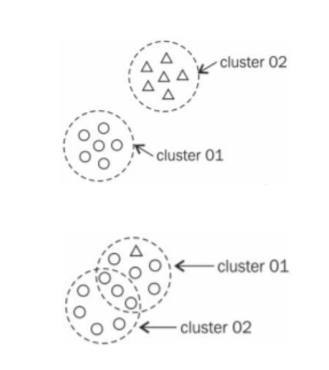
일반 군집화(hard cluster)와 퍼지 군집화(fuzzy cluster)가 있다. 일반 군집화는 데이터가 하나의 군집에만 소속되는 것으로, k-means 알고리즘이 그 예이다. 퍼지 군집화는 데이터가 여러 군집에 부분적으로 소속되는 것으로, 퍼지 k-means 알고리즘이 그 예이다.
군집화의 용도
- 데이터에 내재된 구조(underlying structure) 추정
- 데이터의 전반적 구조 통찰
- 가설 설정과 이상치(anomaly, outlier) 감지
- 데이터 압축(동일 군집의 데이터를 같은 값으로 표현)
- 데이터 전처리(preprocessing) 작업
군집화의 성능 (평가)
군집 내의 분산과 군집간의 거리를 통해 알 수 있다.
밀도 추정(Density estimation)
부류(class)별 데이터를 만들어 냈을 것으로 추정되는 확률분포을 찾는 것이다. 밀도 추정은 각 부류 별로 주어진 데이터를 발생시키는 확률 계산, 가장 확률이 높은 부류로 분류하는 것에 사용된다.
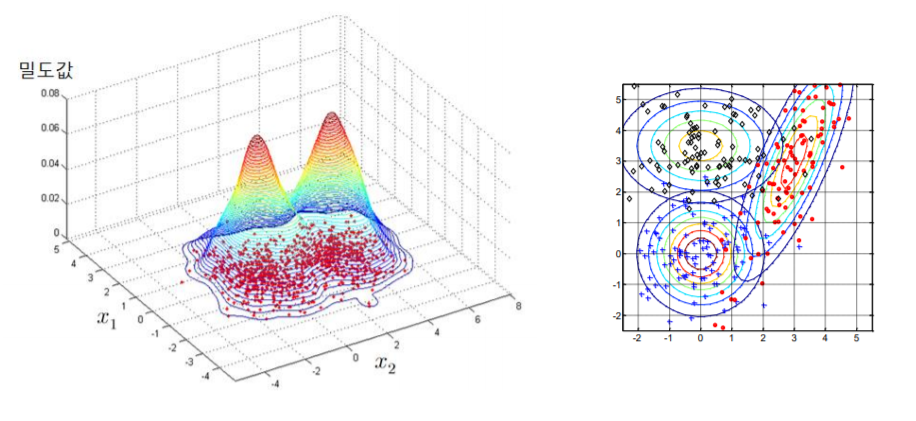
밀도 추정(Density estimation)의 종류
1) 모수적(parametric) 밀도 추정
분포가 특정 수학적 함수의 형태를 가지고 있다고 가정
주어진 데이터를 가장 잘 반영하도록 함수의 파라미터 결정
전형적인 형태 : 가우시안(Gaussian) 함수 또는 여러 개의 가우시안 함수의 혼합(Mixture of Gaussian)
2) 비모수적(nonparametric) 밀도 추정
분포에 대한 특정 함수를 가정하지 않고, 주어진 데이터를 사용하여 밀도함수의 형태 표현
전형적인 형태 : 히스토그램(histogram)
차원축소 (Dimension reduction)
차원축소란 고차원의 데이터 정보의 손실을 최소화 하면서 저차원으로 변환하는 것이다. 차원축소는 2,3차원으로 변환하여 시각화하면 직관적인 데이터 분석이 가능하고, 차원의 저주(curse of dimensionality) 문제를 완화할 수 있다.
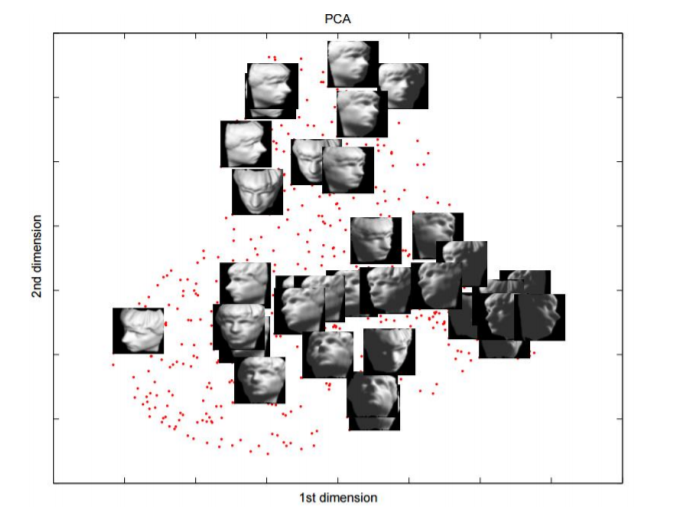
차원의 저주(curse of dimensionality)
차원의 저주란 3차원 물리적 공간과 같은 저차원 설정에서 발생하지 않고, 고차원 공간 (보통 수백 또는 수천 차원)에서 데이터를 분석하고 구성할 때 발생하는 다양한 현상을 말한다. 차원이 커질수록 거리분포가 일정해지고, 차원이 증가함에 따라 부분공간의 개수가 기하급수적으로 증가한다.
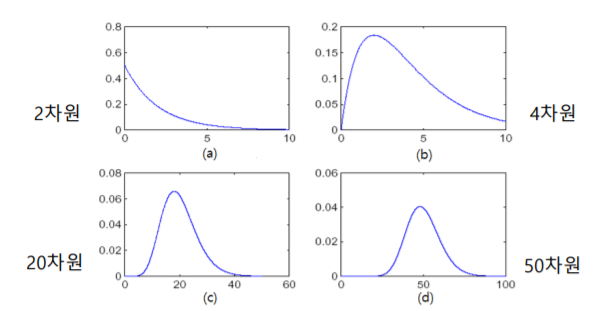

결과적으로 차원축소의 목적은 고차원에 있는 원래 데이터를 유용한 정보의 손실을 최소화 하면서 더 낮은 차원으로 데이터를 대응시키는 것이다.
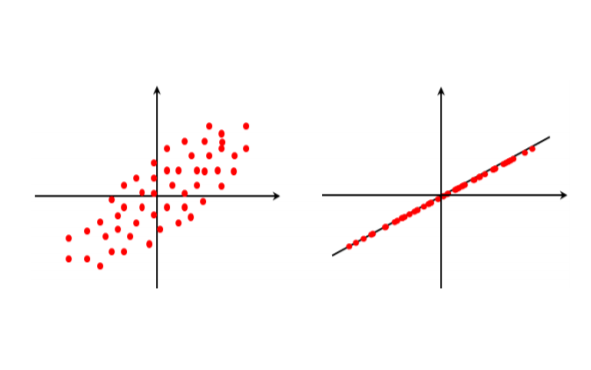
주성분 분석(Principle Component Analysis, PCA)
주성분 분석은 차원 축소에 사용되는 대표적인 방법이다. 분산이 큰 몇개의 축들을 기준으로 데이터를 투영(projection)하여 저차원으로 변환한다. 또한 데이터의 공분산행렬(covariance matrix)에 대한 고유값(eigenvalue) 가 큰 소수의 고유벡터(eigenvector)를 사상 축으로 선택한다.
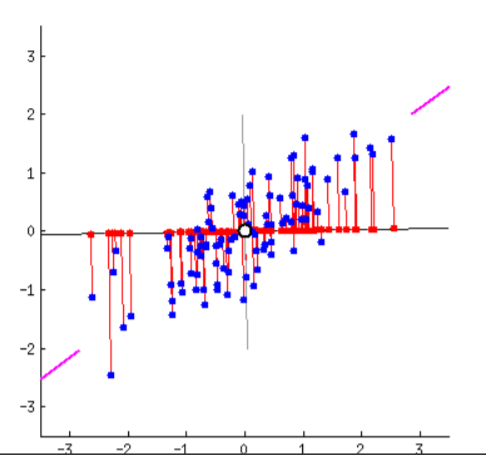
이상치(Outlier) 탐지
이상치는 다른 데이터와 크게 달라서 다른 메커니즘에 의해 생성된 것이 아닌 지 의심스러운 데이터이며 관심 대상이다.
잡음(noise)은 관측 오류, 시스템에서 발생하는 무작위적인 오차이고 관심이 없는 제거할 대상이다.
이상치(outlier) 탐지의 종류
1) 점 이상치(point outlier)
다른 데이터와 비교하여 차이가 큰 데이터
2) 상황적 이상치(contextual outlier)
상황에 맞지 않는 데이터
예) 여름철에 25도인 데이터는 정상, 겨울철에 25도는 이상치
3) 집단적 이상치(collective outlier)
여러 데이터를 모아서 보면 비정상으로 보이는 데이터들의 집단
이상치(outlier) 탐지의 사용
- 부정사용감지 시스템(fraud detection system, FDS)
이상한 거래 승인 요청 시에 카드 소유자에게 자동으로 경고 메시지 전송
- 침입탐지 시스템(intrusion detection system, IDS)
네트워크 트래픽을 관찰하여 이상 접근 식별
- 시스템의 고장 진단
- 임상에서 질환 진단 및 모니터링
- 공공보건에서 유행병의 탐지
- 스포츠 통계학(Sabermetrics)에서 특이 사건 감지
- 관측 오류의 감지
'📁 AI' 카테고리의 다른 글
| #02-2. 지도학습의 종류 - 회귀 (0) | 2020.05.04 |
|---|---|
| [Machine Learning] 지도학습의 종류 - 분류 (0) | 2020.05.03 |
| [Machine Learning] 지도학습의 개념과 종류 (0) | 2020.05.03 |
| [Machine Learning] 기계학습의 의미와 기계학습 종류 (0) | 2020.05.03 |
| [Machine Learning] 앙상블 학습(Ensemble Learning), 배깅(Bagging)과 부스팅(Boosting) (0) | 2020.04.04 |



