분류(Classification)
분류란 입력 데이터 값을 정해진 몇 개의 부류(Class)로 대응시키는 문제이다. 분류 문제의 학습은 학습 데이터를 잘 분류할 수 있는 함수(수학적 함수, 규칙or패턴)를 찾는 것이다. 함수의 형태는 수학적 함수일 수도 있고 규칙일 수도 있다.
분류기(Classifier)란 학습된 함수를 이용하여 데이터를 분류하는 프로그램이다. 이상적인 분류기는 학습에 사용되지 않은 데이터에 대해서 분류를 잘 하는것으로 일반화(Generalization) 능력이 좋은 것으로 볼 수 있다.
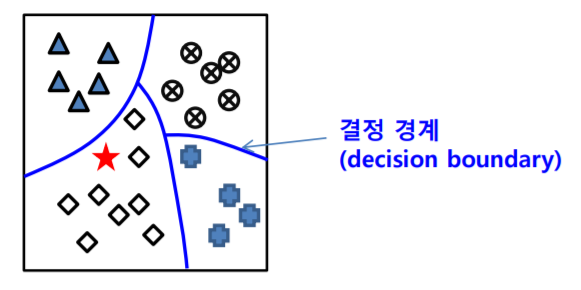
분류기 학습 알고리즘
- 결정트리(decision tree) 알고리즘
- K-근접이웃 (K-nearest neighbor, KNN) 알고리즘
- 다층 퍼셉트론 신경망
- 딥러닝(deep learning) 신경망
- 서포트 벡터 머신(Support Vector Machine, SVM)
- 에이다부스트(AdaBoost)
- 랜덤 포리스트(random forest)
- 확률 그래프 모델 (probabilistic graphical model)
=> 문제에 최적인 것을 선택해서 사용하면 된다.
데이터의 구분
데이터는 학습 데이터(Training Data), 테스트 데이터(Test Data), 검증 데이터(Validation Data)로 나눌 수 있다.
1) 학습 데이터(training data)
- 분류기(classifier)를 학습하는데 사용하는 데이터 집합으로, 학습 데이터가 많을 수록 유리하다.
2) 테스트 데이터(test data)
- 만들어진 모델이 얼마나 좋은지 test하는 데이터로, 학습된 모델의 성능을 평가하는데 사용하는 데이터 집합이다. 이 데이터는 학습에 사용되지 않은 데이터이다.
3) 검증 데이터(validation data)
- 학습 과정에서 학습을 중단할 시점을 결정하기 위해 사용하는 데이터 집합이다. 학습이 100% 정확한 것이 마냥 좋은 것만은 아니다.
과적합(overfitting)과 부적합(underfitting)
과적합은 학습 데이터에 대해서 지나치게 잘 학습된 상태를 말한다. 데이터는 오류나 잡음을 포함할 개연성이 크기 때문에, 학습 데이터에 대해 매우 높은 성능을 보이더라도 학습되지 않은 데이터에 대해 좋지 않은 성능을 보일 수 있다. 부적합은 학습 데이터를 충분히 학습하지 않은 상태를 말한다.
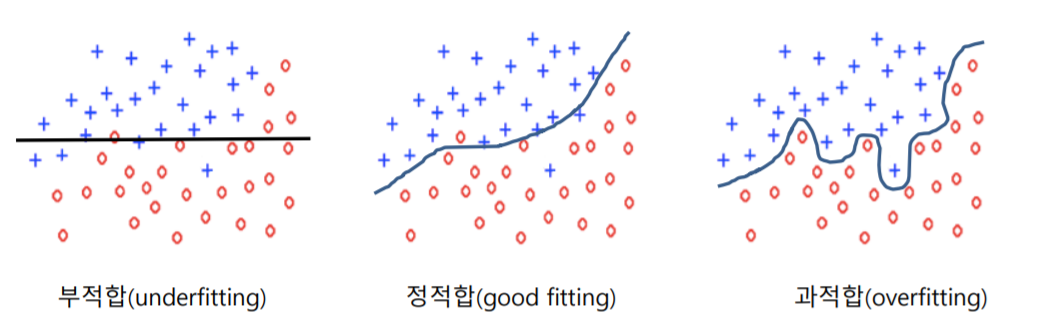
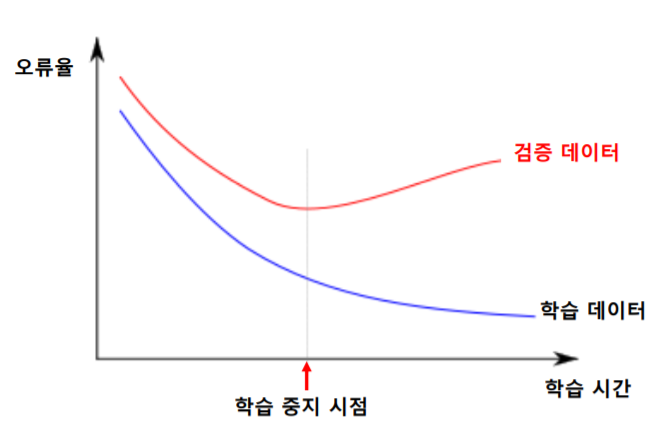
과적합 회피 방법
학습을 진행할수록 오류를 개선할 수 있지만 지나친 학습은 과적합을 발생시킨다. 학습 과정에서 별도의 검증 데이터(Validation Data)에 대한 성능을 평가하는 방법으로 과적합을 회피할 수 있다. 검증데이터에 대한 오류가 감소하다가 증가하는 시점에 학습을 중단하면 된다.
분류기의 성능 평가
분류기의 성능은 정확도(Accuracy)로 평가된다. 테스트데이터에 대한 정확도를 분류기의 정확도로 사용한다.
정확도 = (옳게 분류한 데이터 개수) / (전체 데이터 개수)
정확도가 높은 분류기를 학습하기 위해서는 많은 학습데이터를 사용하는 것이 유리하다. 또한 학습데이터와 테스트데이터는 겹치지 않도록 해야한다.
데이터가 부족한 경우의 성능평가
별도의 테스트 데이터를 확보하면 비효율적이므로, 가능하면 많은 데이터를 학습에 사용하면서 성능을 평가하는 방법이 필요하다. 따라서 데이터가 부족한 경우의 성능평가는 k-겹 교차검증(k-fold cross-validation)을 사용한다.
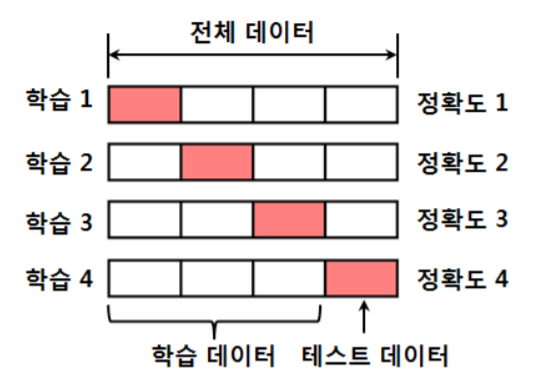
k-겹 교차검증(k-fold cross-validation)이란 전체 데이터를 k등분하고, 각 등분을 한번씩 테스트 데이터로 사용하여 성능평가를 한 후 평균값을 선택하는 방법이다. cf) 테스트 데이터의 목적은 성능 향상!
불균형 부류 데이터(imbalanced class data) 문제
불균형 부류 데이터 문제란 특정 부류에 속하는 학습 데이터의 개수가 다른 부류에 비하여 지나치게 많은 경우를 말한다. 이러한 경우에는 정확도에 의한 성능평가는 무의미하다. 예를 들어, A 부류의 데이터가 전체의 99%인 경우, 분류기의 출력을 항상 A 부류로 하더라도 정확도는 99%가 된다. 이러한 결과는 단순히 정확도만 보게 된다면 의미없는 분류기이다.
불균형 부류 데이터(imbalanced class data) 문제의 대응방안
1) 가중치를 고려한 정확도 척도 사용
불균형 부류 데이터 문제를 해결하기 위해 가중치를 고려한 정확도 척도를 사용한다. 많은 학습 데이터를 갖는 부류에 대해서 재표본추출(re-sampling)을 하고, 적은 학습데이터를 갖는 부류에 대해서는 인공적인 데이터를 생성해 낸다.
2) SMOTE(Synthetic Minority Over-sampling Technique) 알고리즘
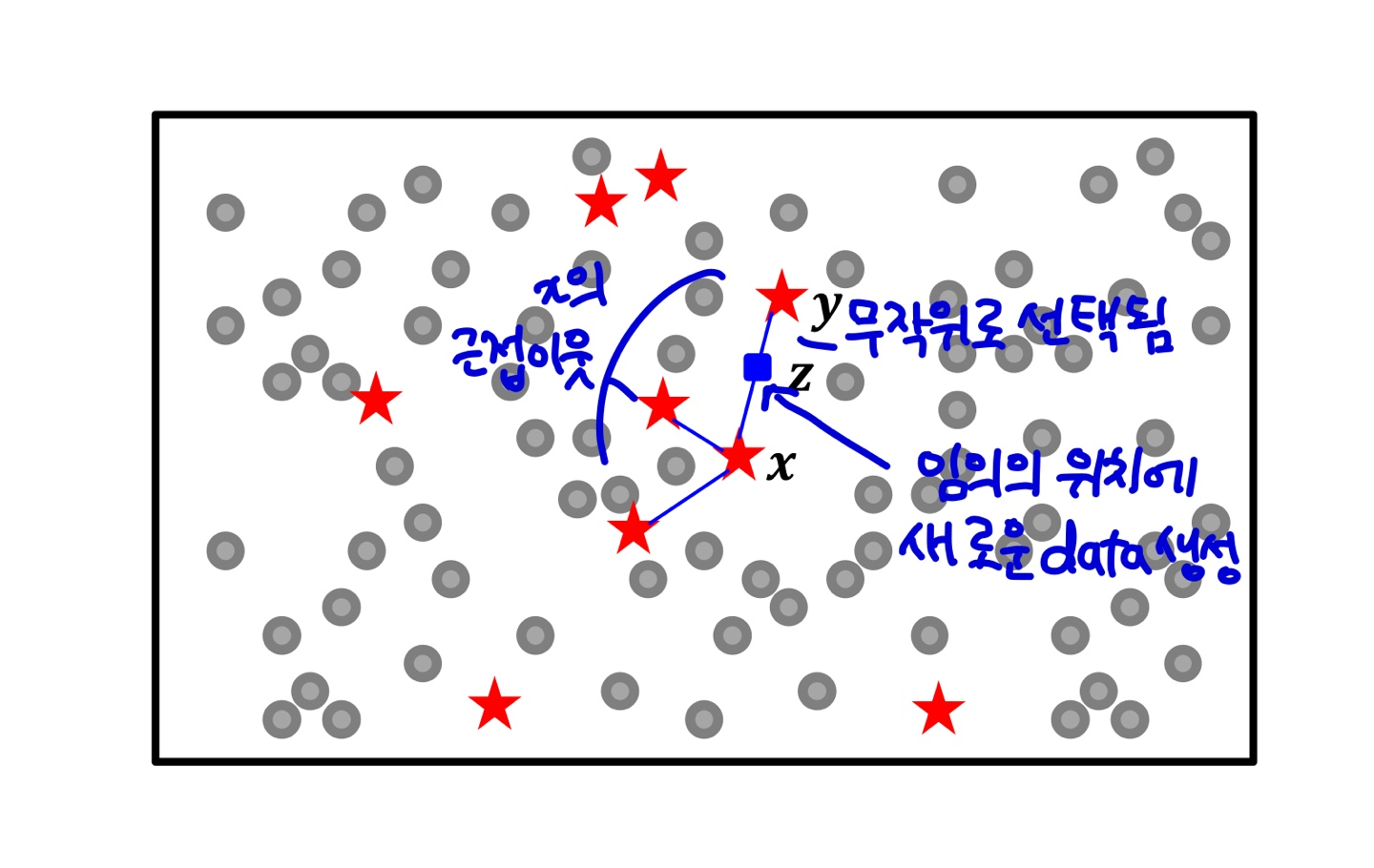
SMOTE 알고리즘은 빈도가 낮은 부류의 학습 데이터를 인공적으로 만들어 내는 방법이다.
i) 임의의 낮은 빈도 부류의 학습 데이터 x를 선택한다.
ii) x의 k-근접이웃(k-nearest neighbor, KNN)인 같은 부류의 데이터를 선택한다.
iii) k-근접이웃중에 무작위로 하나(y)를 선택한다.
iv) x와 y를 연결하는 직선 상의 무작위 위치에 새로운 데이터를 생성한다.
이진 분류기의 성능평가
이진 분류기란 두 개의 부류만을 갖는 데이터에 대한 분류기이다. (A|B, Yes|No)
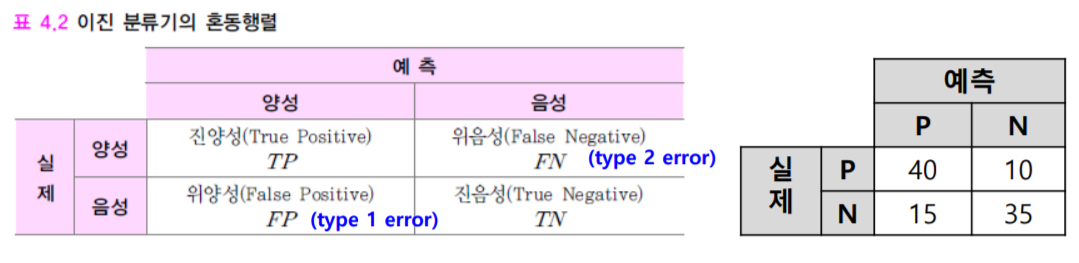
1) 이진 분류기의 혼동 행렬


2) ROC 곡선 : 임계값에 따라 성능을 결정한다.
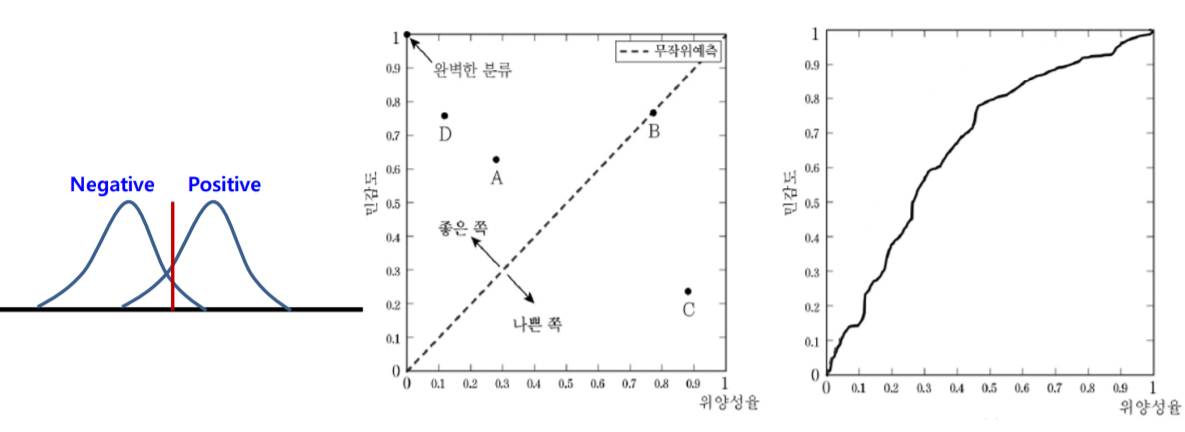
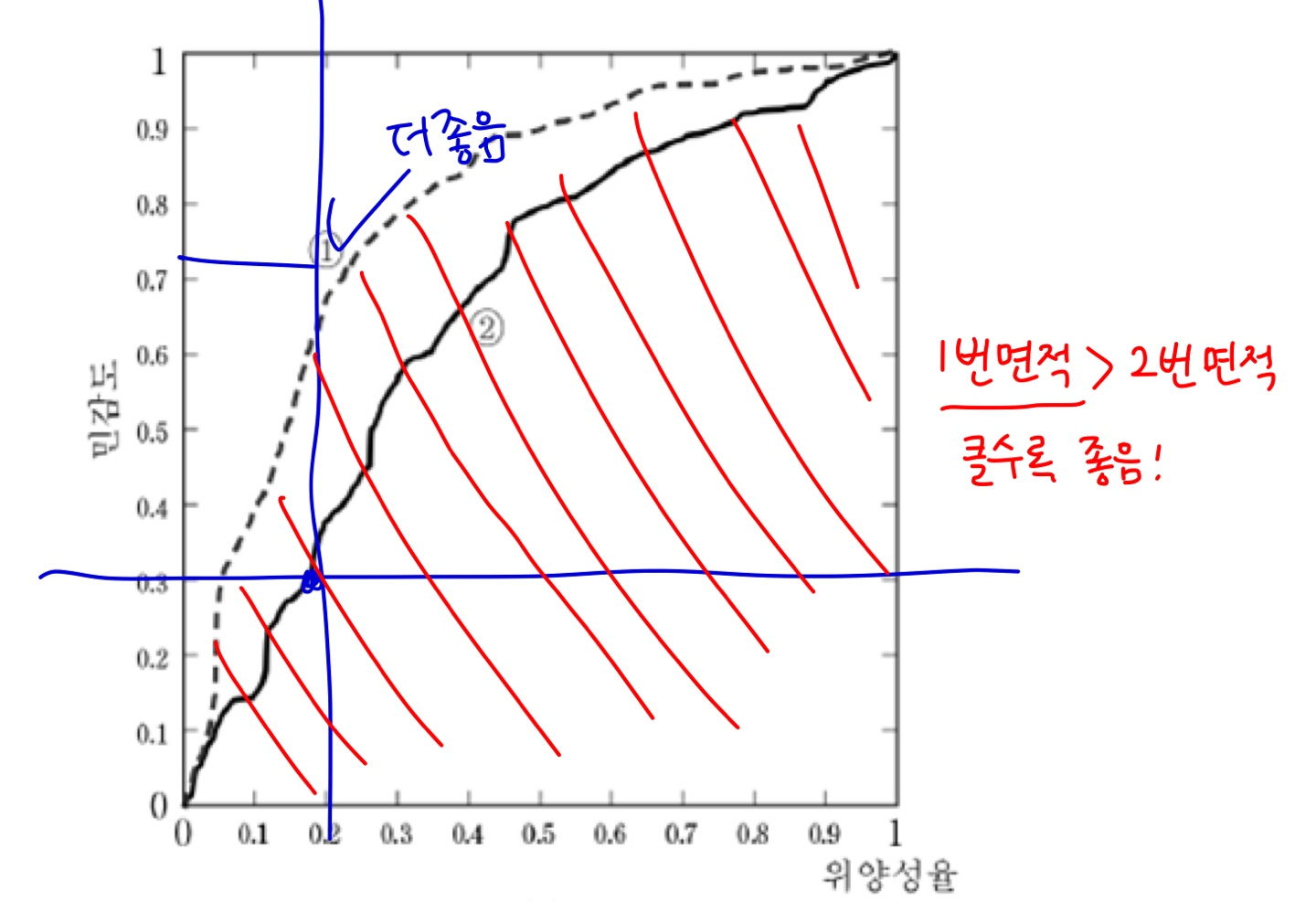
AUC(Area Under the Curve)란 ROC 곡선에서 곡선 아래부분의 면적을 말한다. AUC가 클수록 바람직한 분류기이다.
'📁 AI' 카테고리의 다른 글
| [Machine Learning] 결정트리(Decision tree) 학습 (0) | 2020.05.04 |
|---|---|
| #02-2. 지도학습의 종류 - 회귀 (0) | 2020.05.04 |
| [Machine Learning] 지도학습의 개념과 종류 (0) | 2020.05.03 |
| [Machine Learning] 비지도학습의 개념과 비지도학습 문제 (0) | 2020.05.03 |
| [Machine Learning] 기계학습의 의미와 기계학습 종류 (0) | 2020.05.03 |



